dots.llm1: 先进的MoE语言模型
一个强大的MoE模型,在总共142B参数中仅激活14B参数,
性能与最先进的模型相当,同时保持卓越的效率。
🧠 32K上下文长度 | 🌍 多语言支持(英文/中文)
dots.llm1 由先进技术驱动



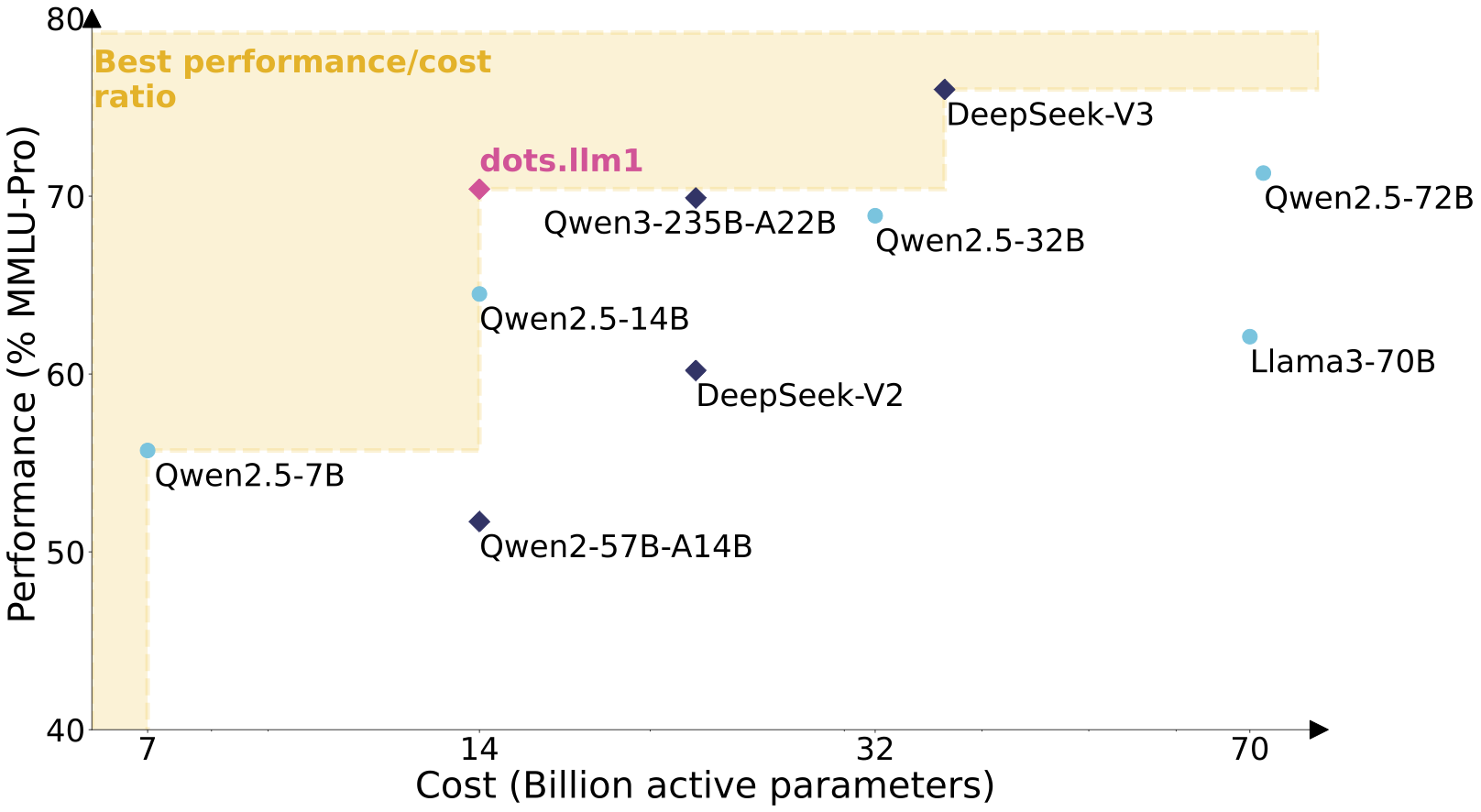
什么是 dots.llm1
dots.llm1 是一种大规模 MoE 模型,在 142B 总参数中仅激活 14B 参数,在保持高效率的同时提供卓越性能。
- 先进的 MoE 架构精细的 MoE 架构利用 128 个路由专家中的前 6 个,外加 2 个共享专家,实现最佳性能。
- 高质量训练使用三阶段数据处理框架,在 11.2T 高质量标记上训练,无需合成数据。
- 长上下文支持32,768 标记上下文长度,支持处理大量文档和复杂对话。
为什么选择 dots.llm1
体验具有卓越效率和性能的最先进大型语言模型的优势。



如何使用 dots.llm1
通过四个简单步骤开始使用 dots.llm1:
dots.llm1 核心功能
探索使 dots.llm1 在语言模型领域脱颖而出的前沿功能。
专家混合系统
MoE 架构拥有 142B 总参数但仅激活 14B,同时提供性能和效率。
32K 上下文长度
扩展的上下文窗口允许处理冗长的文档和复杂的对话。
多语言能力
在英语和中文方面表现出色,支持多样化应用。
优化推理
通过 vLLM、sglang 和 Hugging Face 多种部署选项,实现快速高效的推理。
Docker 集成
通过容器化环境轻松部署,确保跨基础设施的一致性能。
研究透明度
访问中间检查点和全面技术报告,用于模型分析。
dots.llm1 性能
展示卓越能力的基准测试。
总参数量
142B
参数
激活参数
14B
参数
上下文长度
32K
标记
dots.llm1 的应用
探索不同行业如何利用 dots.llm1 的能力。
自然语言处理
研究与开发
dots.llm1 凭借其庞大的参数规模和高效架构,支持高级文本分析、情感理解和语义处理。
内容生成
媒体与出版
借助 dots.llm1 多样化的能力和扩展的上下文长度,创建多语言高质量内容,实现全面理解。
对话式 AI
客户支持
构建复杂的聊天机器人和虚拟助手,在长对话中保持上下文,同时提供准确有用的回复。
代码分析
软件开发
利用 dots.llm1 对编程概念的深入理解和在上下文窗口中处理大型代码库的能力,分析和生成代码。
文档处理
法律与金融
处理并从冗长的法律或金融文档中提取见解,利用模型的 32K 标记上下文长度实现全面理解。
多语言应用
全球企业
凭借 dots.llm1 在英语和中文方面的出色表现,支持国际业务运营,实现无缝跨语言应用。
关于 dots.llm1 的常见问题
还有更多问题?访问我们的 GitHub 仓库或 HuggingFace 页面。
dots.llm1 是什么,它有什么特别之处?
dots.llm1 是一个大规模的混合专家系统 (MoE) 语言模型,在 142B 总参数中仅激活 14B 参数。它的特别之处在于卓越的效率与性能比率,提供与更大模型相当的能力,同时使用显著更少的计算资源。
运行 dots.llm1 需要什么硬件要求?
由于 dots.llm1 在推理过程中仅激活 14B 参数,它可以在拥有 24GB+ 显存的消费级 GPU 上运行。为了通过 vLLM 或 sglang 获得最佳性能,我们建议使用多 GPU 进行张量并行处理。
dots.llm1 支持哪些语言?
dots.llm1 在英语和中文方面都有强大能力,使其适用于多语言应用。它在覆盖这两种语言的多样化数据集上进行了训练。
如何在我的应用中部署 dots.llm1?
您可以使用我们的 Docker 镜像与 vLLM 部署 dots.llm1 以获得 OpenAI 兼容的 API,直接使用 Hugging Face Transformers 进行集成,或使用 sglang 进行高性能服务。我们在文档中提供了所有这些方法的示例。
dots.llm1 的上下文长度是多少?
dots.llm1 支持 32,768 标记的上下文长度,允许处理非常长的文档并在广泛的对话中保持上下文。这使其特别适用于需要分析长文本的应用。
dots.llm1 适合研究用途吗?
当然!我们在预训练过程中发布了每万亿标记训练的中间检查点,提供了前所未有的模型学习动态透明度。这使 dots.llm1 对研究大型语言模型发展的研究人员特别有价值。
今天就开始使用 dots.llm1
体验高效大型语言模型的力量。