dots.llm1: Advanced MoE Language Model
A powerful MoE model with 14B activated parameters out of 142B total parameters.
Performance on par with state-of-the-art models with exceptional efficiency.
🧠 32K context length | 🌍 Multilingual (EN/CN)
dots.llm1 is powered by advanced technologies



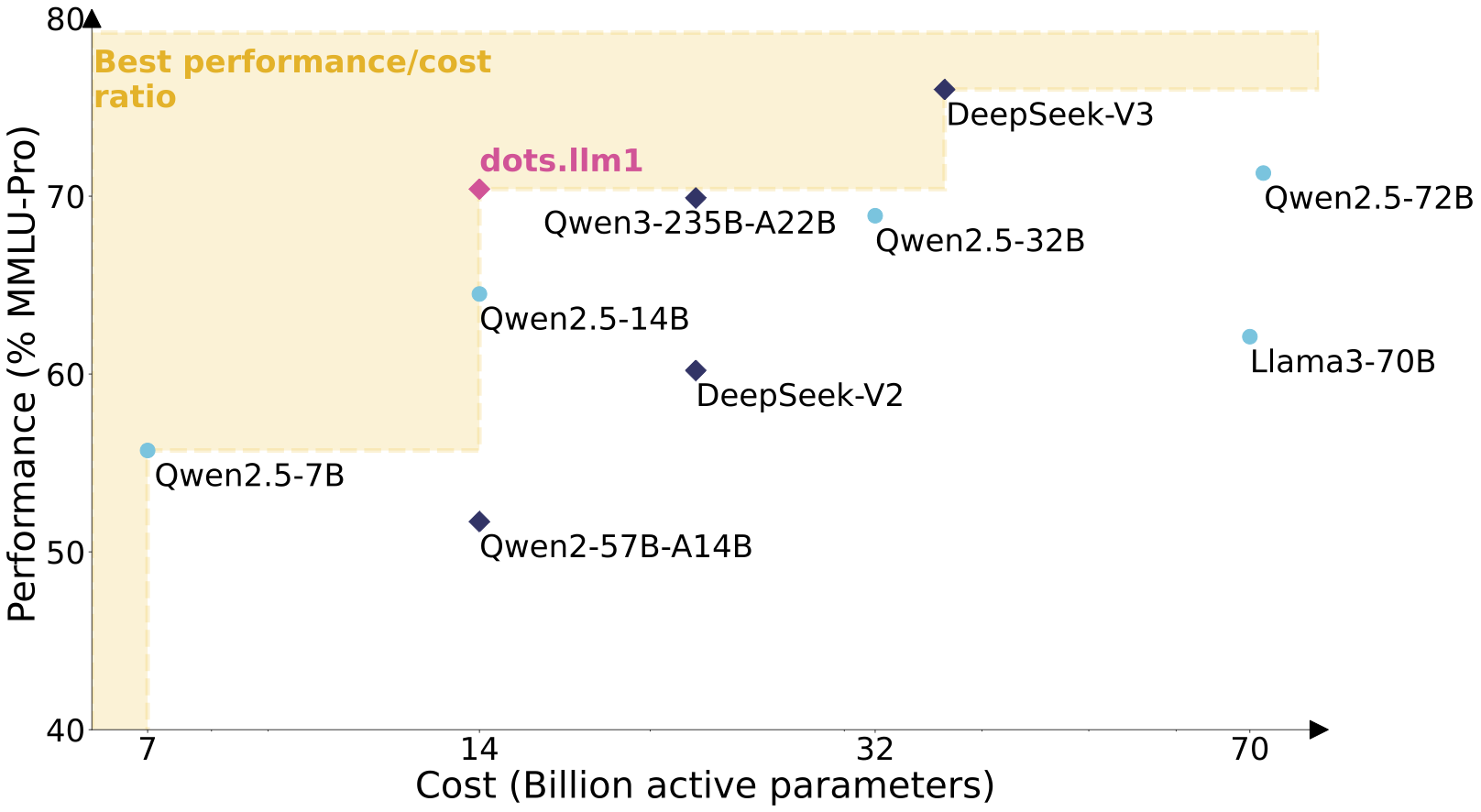
What is dots.llm1
dots.llm1 is a large-scale MoE model that activates 14B parameters out of 142B total, delivering exceptional performance while maintaining efficiency.
- Advanced MoE ArchitectureFine-grained MoE utilizing top-6 out of 128 routed experts, plus 2 shared experts for optimal performance.
- High-Quality TrainingTrained on 11.2T high-quality tokens without synthetic data using a three-stage data processing framework.
- Long Context Support32,768 token context length allows processing of extensive documents and conversations.
Why Choose dots.llm1
Experience the advantages of a state-of-the-art large language model with exceptional efficiency and performance.



How to Use dots.llm1
Get started with dots.llm1 in four simple steps:
Key Features of dots.llm1
Explore the cutting-edge capabilities that make dots.llm1 stand out in the language model landscape.
Mixture of Experts
MoE architecture with 142B total parameters but only 14B activated, offering both performance and efficiency.
32K Context Length
Extended context window allows processing of lengthy documents and complex conversations.
Multilingual Capability
Strong performance in both English and Chinese, enabling diverse applications.
Optimized Inference
Multiple deployment options with vLLM, sglang, and Hugging Face for fast and efficient inference.
Docker Integration
Easy deployment with containerized environment for consistent performance across infrastructures.
Research Transparency
Access to intermediate checkpoints and comprehensive technical reports for model analysis.
dots.llm1 Performance
Benchmarks showing exceptional capabilities.
Total Parameters
142B
Parameters
Activated
14B
Parameters
Context
32K
Tokens
Applications of dots.llm1
Explore how different industries are leveraging the capabilities of dots.llm1.
Natural Language Processing
Research & Development
dots.llm1 enables advanced text analysis, sentiment understanding, and semantic processing with its extensive parameter scale and efficient architecture.
Content Generation
Media & Publishing
Creating high-quality content across multiple languages with dots.llm1's versatile capabilities and extended context length for comprehensive understanding.
Conversational AI
Customer Support
Building sophisticated chatbots and virtual assistants that maintain context over long conversations while providing accurate and helpful responses.
Code Analysis
Software Development
Analyzing and generating code with dots.llm1's deep understanding of programming concepts and ability to process large codebases within its context window.
Document Processing
Legal & Financial
Processing and extracting insights from lengthy legal or financial documents, leveraging the model's 32K token context length for comprehensive understanding.
Multilingual Applications
Global Businesses
Supporting international operations with dots.llm1's strong performance in both English and Chinese languages, enabling seamless cross-lingual applications.
Frequently Asked Questions About dots.llm1
Have more questions? Visit our GitHub repository or HuggingFace page.
What is dots.llm1 and what makes it special?
dots.llm1 is a large-scale Mixture of Experts (MoE) language model that activates only 14B parameters out of 142B total parameters. What makes it special is its exceptional efficiency-to-performance ratio, delivering capabilities comparable to much larger models while using significantly fewer computational resources.
What hardware requirements are needed to run dots.llm1?
Since dots.llm1 activates only 14B parameters during inference, it can run on consumer-grade GPUs with 24GB+ VRAM. For optimal performance with vLLM or sglang serving, we recommend using multiple GPUs for tensor parallelism.
What languages does dots.llm1 support?
dots.llm1 has strong capabilities in both English and Chinese languages, making it suitable for multilingual applications. It was trained on diverse datasets covering both languages.
How can I deploy dots.llm1 in my application?
You can deploy dots.llm1 using our Docker image with vLLM for an OpenAI-compatible API, integrate it directly using Hugging Face Transformers, or use sglang for high-performance serving. We provide examples for all these methods in our documentation.
What is the context length of dots.llm1?
dots.llm1 supports a context length of 32,768 tokens, allowing it to process very long documents and maintain context over extensive conversations. This makes it particularly useful for applications requiring analysis of lengthy text.
Is dots.llm1 suitable for research purposes?
Absolutely! We've released intermediate checkpoints at every trillion tokens trained during the pretraining process, providing unprecedented transparency into model learning dynamics. This makes dots.llm1 particularly valuable for researchers studying large language model development.
Start Using dots.llm1 Today
Experience the power of efficient large language models.